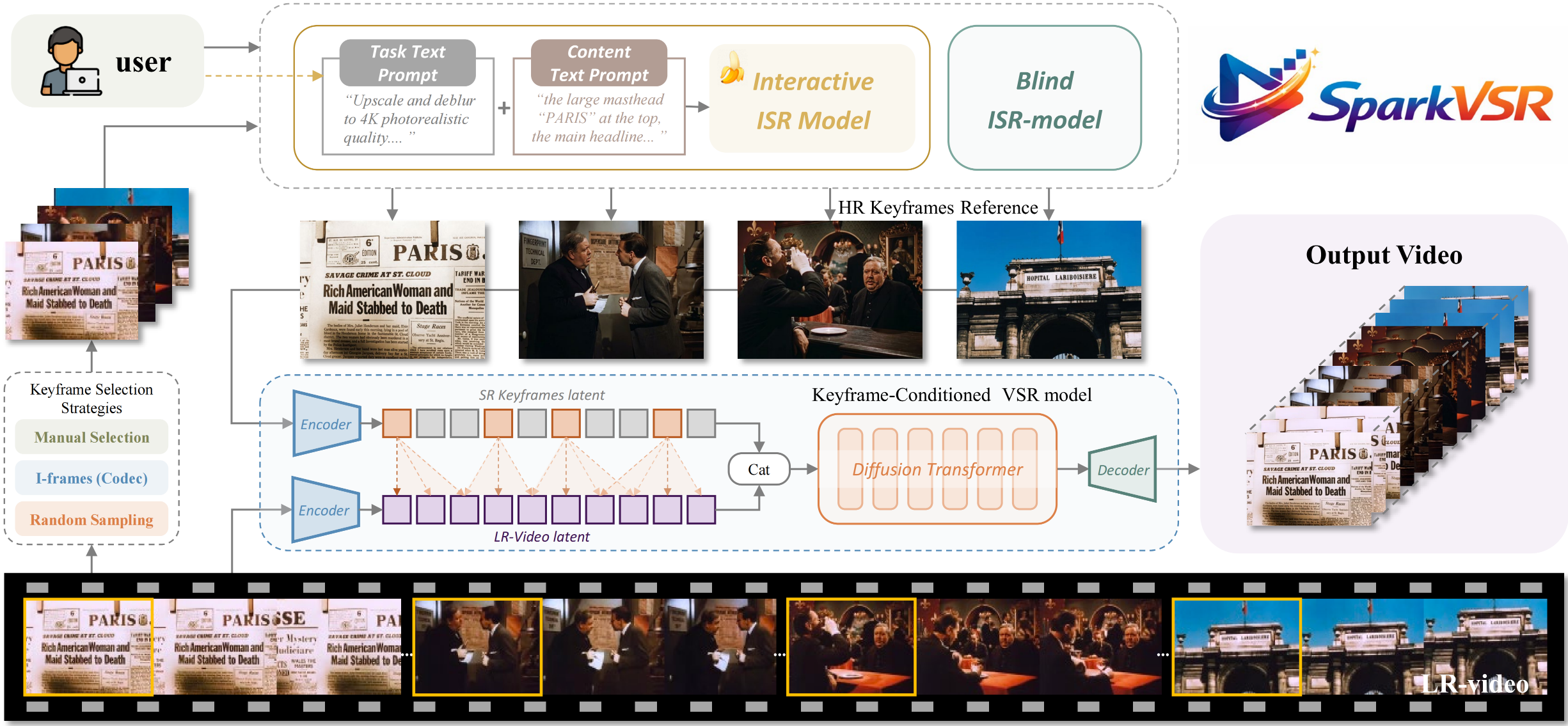
SparkVSR
Interactive Video Super-Resolution via Sparse Keyframe Propagation
1Texas A&M University 2YouTube, Google
† Corresponding author
1Texas A&M University 2YouTube, Google
† Corresponding author
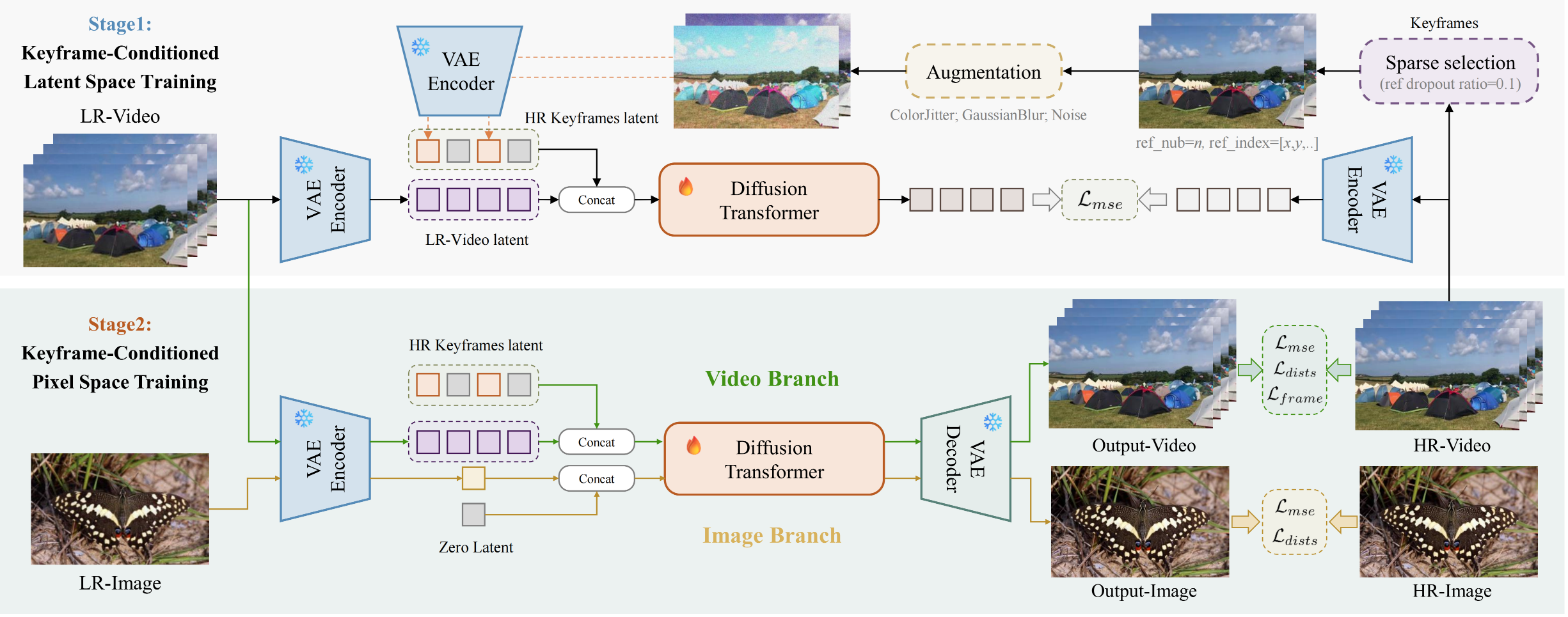
Keyframe-conditioned two-stage training pipeline of SparkVSR. (1) Stage 1 (Latent Space Training): Augmented HR keyframe latents are concatenated with LR video latents to optimize the Diffusion Transformer using $\mathcal{L}_{mse}$. (2) Stage 2 (Pixel Space Training): A joint video-image training mechanism is employed. The video branch is conditioned on HR keyframe latents, while the image branch uses a zero latent. Finally, outputs are decoded by the VAE and refined in the pixel space using mixed losses.
Swipe or use arrows to browse more results in each category
💡 Drag the slider left/right to compare input and super-resolution result. Use arrows to browse more clips.
@misc{yu2026sparkvsrinteractivevideosuperresolution,
title={SparkVSR: Interactive Video Super-Resolution via Sparse Keyframe Propagation},
author={Jiongze Yu and Xiangbo Gao and Pooja Verlani and Akshay Gadde and Yilin Wang and Balu Adsumilli and Zhengzhong Tu},
year={2026},
eprint={2603.16864},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2603.16864},
}